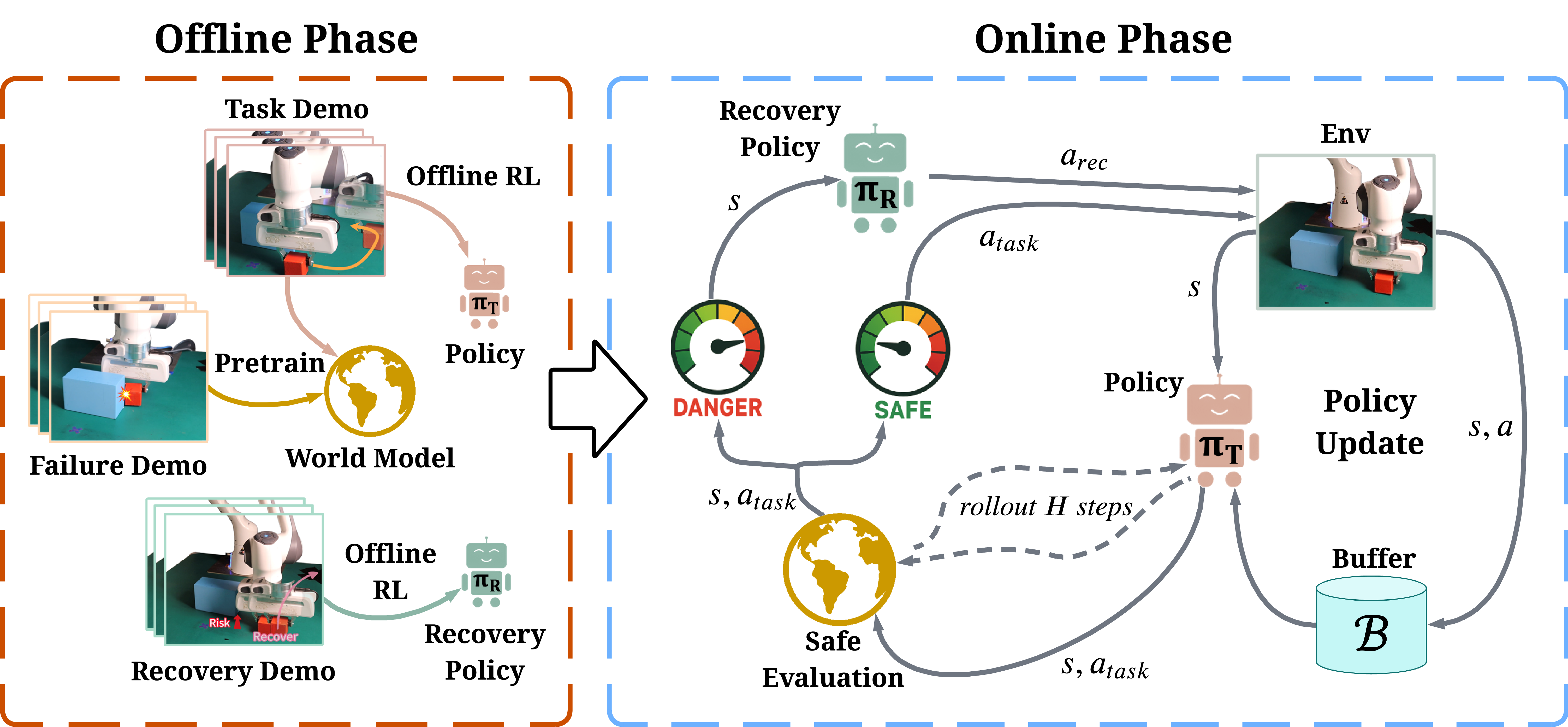
FARL is a failure-aware offline-to-online RL framework with two phases:
- Offline: Pre-train task policy \(\pi_{\text{task}}\), recovery policy \(\pi_{\text{rec}}\), and a world model.
- Policies: behavior cloning → offline PPO-style fine-tuning.
- World model: predicts short-horizon rewards, values, and a constraint signal capturing near-future failure risks.
- Online: Fix \(\pi_{\text{rec}}\) and world model; only fine-tune \(\pi_{\text{task}}\) in the real world.
- World model rolls out \(\pi_{\text{task}}\) and estimates near-future failure cost \(C_H\).
- If \(C_H \le \varepsilon_{\text{safe}}\): execute task action; otherwise: switch to recovery.
- Task policy updated via PPO on safety-filtered transitions.
